


Apache Spark 101 for Data Engineering
What is Apache Spark and why it is so popular among Data Engineers?

We all know this right?

90% of the world’s data was generated in just the last 2 years. The 120 zettabytes generated in 2023 are expected to increase by over 150% in 2025, hitting 181 zettabytes

In the early 2000s, the amount of data being generated exploded exponentially with the use of the internet, social media, and various digital technologies. Organizations found themselves facing a massive volume of data that was very hard to process. To address this challenge, the concept of Big Data emerged.

Big Data refers to extremely large and complex data sets that are difficult to process using traditional methods. Organizations across the world wanted to process this massive volume of data and derive useful insights from it.
Here's where Hadoop comes into the picture.

In 2006, a group of engineers at Yahoo developed a special software framework called Hadoop. They were inspired by Google's MapReduce and Google File System technology. Hadoop introduced a new way of data processing called distributed processing.
Instead of relying on a single machine, we can use multiple computers to get the final result.
Think of it like teamwork: each machine in a cluster will get some part of the data to process. They will work simultaneously on all of this data, and in the end, we will combine the output to get the final result.

There are two main key components of Hadoop.
Hadoop Distributed File System (HDFS): This is like the giant storage system for keeping our dataset. It divides our data into multiple chunks and stores all of this data across different computers.
MapReduce: This is a super smart way of processing all of this data together. MapReduce helps in processing all of this data in parallel. So, you can divide your data into multiple chunks and process them together, similar to a team of friends working to solve a very large puzzle. Each person in the team gets a part of the puzzle to solve, and in the end, we put everything together to get the final result.
It allowed organizations to store and process very large volumes of data.
But here's the thing, although Hadoop was very good at handling Big Data, there were a few limitations.
One of the biggest problems behind Hadoop was that it relied on storing data on disk, which made things much slower. Every time we run a job, it stores the data onto the disk, reads it, processes it, and then stores it again through a disk. This made the data processing a lot slower.
Another issue with Hadoop was that it processed data only in batches. This means we had to wait for one process to complete before submitting any other job. It was like waiting for the whole group of friends to complete their puzzles individually and then put them together.
So, processing all of this data was needed faster and in real time. Here's where Apache Spark comes into the picture.

In 2009, researchers at the University of California, Berkeley, developed Apache Spark as a research project. The main reason behind the development of Apache Spark was to address the limitations of Hadoop. This is where they introduced the powerful concept called RDD (Resilient Distributed Dataset).
RDD is the backbone of Apache Spark. It allows data to be stored in memory and enables faster data access and processing. Instead of reading and writing the data repeatedly from the disk, Spark processes the entire data in just memory.
The meaning of memory here is the RAM (Random Access Memory) stored inside our computer. And this in-memory processing of data makes Spark 100 times faster than Hadoop.
Additionally, Spark also gave the ability to write code in various programming languages such as Python, Java, and Scala. So, you can easily start writing Spark applications in your preferred language and process your data on a large scale.
Apache Spark became very famous because it was fast, could handle a lot of data, and process it efficiently.

Components attached to Apache Spark.
Spark Core: Manages basic data processing tasks across multiple machines.
Spark SQL: Allows you to run SQL queries directly on datasets.
Spark Streaming: Facilitates real-time data processing.
MLlib: Machine learning library to run large-scale machine learning models.
With all of these components working together, Apache Spark became a powerful tool for processing and analyzing Big Data.
Nowadays, in any company, you will see Apache Spark being used to process Big Data.
Apache Spark Architecture

When you think of a computer, a standalone computer is generally used to watch movies, play games, or anything else. But you can't do that on a single computer when you want to process large Big Data. You need multiple computers working together on individual tasks so that you can combine the output at the end and get the desired result.

You can't just take ten computers and start processing your Big Data. You need a proper framework to coordinate work across all of these different machines, and Apache Spark does exactly that.
Apache Spark manages and coordinates the execution of tasks on data across a cluster of computers. It has something called a cluster manager. When we write any job in Spark, it is called a Spark application. Whenever we run anything, it goes to the cluster manager, which grants resources to all applications so that we can complete our work.

Apache Spark coordinates tasks across multiple computers using a cluster manager, which allocates resources to various applications within Spark. The framework includes two critical components:
Driver Processes: Acts as the manager, overseeing the application's operations.
Executor Processes: Performs the actual data processing tasks as directed by the driver.
The driver processes are like a boss, and the executor processes are like workers.
The main job of the driver processes is to keep track of all the information about the Apache Spark application. It will respond to the command and input from the user.
So, whenever we submit anything, the driver process will make sure it goes through the Apache Spark application properly. It analyzes the work that needs to be done, divides our work into smaller tasks, and assigns these tasks to executor processes.
So, it is the boss or a manager who is trying to make sure everything works properly.
The driver process is the heart of the Apache Spark application because it makes sure everything runs smoothly and allocates the right resources based on the input that we provide.
Executor processes are the ones that do the work. They execute the code assigned by the driver process and report back the progress and result of the computation.
How Apache Spark executes the code
When we write our code in Apache Spark, the first thing we need to do is create the Spark session. It is making the connection with the cluster manager. You can create a Spark session with any of these languages: Python, Scala, or Java. No matter what language you use to begin writing your Spark application, the first thing you need to create is a Spark session.
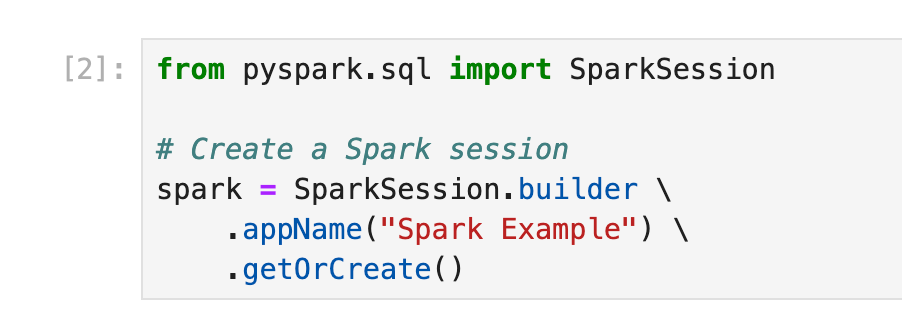
Step 1: Setting Up the Spark Session
The Spark session is the entry point for programming Spark applications. It lets you communicate with Spark clusters and is necessary for working with RDDs, DataFrames, and Datasets.
Step 2: Creating a DataFrame
We'll create a DataFrame containing a range of numbers from 0 to 999, which we'll use for further transformations.

Step 3: Applying Transformations
Let's apply a transformation to filter out all even numbers from the DataFrame. Remember, transformations in Spark are lazily evaluated, which means no computation happens until an action is called

Step 4: Executing Actions
Now we will use an action to trigger the computation of the transformed data. We'll count the number of even numbers found in our DataFrame.

Step 5: Running SQL Queries
To showcase Spark SQL, let's create a temporary view using our DataFrame and run a SQL query against it.
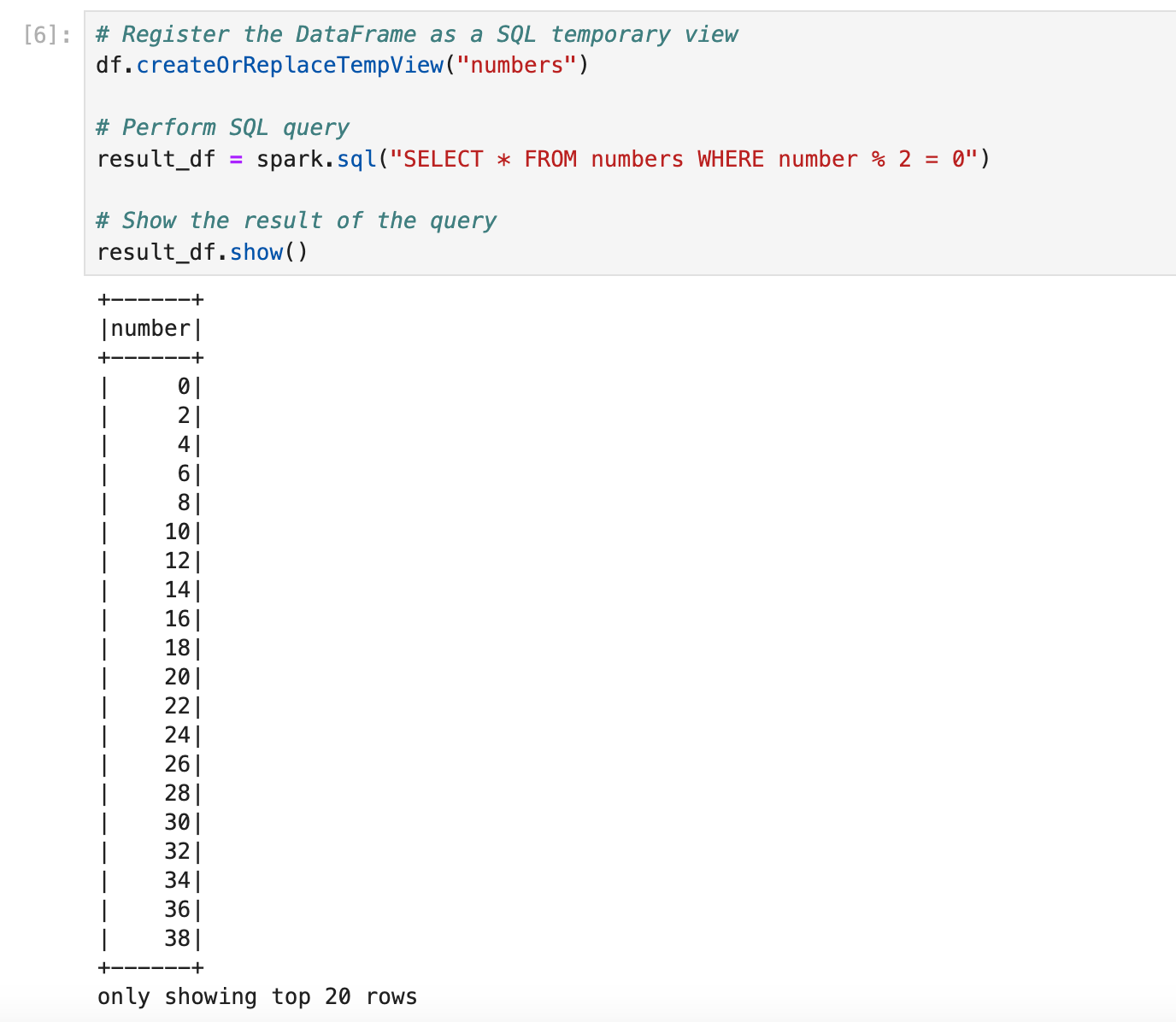
That’s it, you just ran your first Spark code where you created SparkSession, DataFrame, Transformation, Action, and applied SQL query on top of it.
This is just a quick guide there are many things you might need to understand to learn Spark properly
Structured API
Lower Level API
Running Spark Code in Production
Databricks and DeltaLake
Lakehouse Architecture
Distributed Shared Variables
and many more…
If you are interested in learning Apache Spark In-Depth with 2 End-To-End Projects on AWS and Azure like this
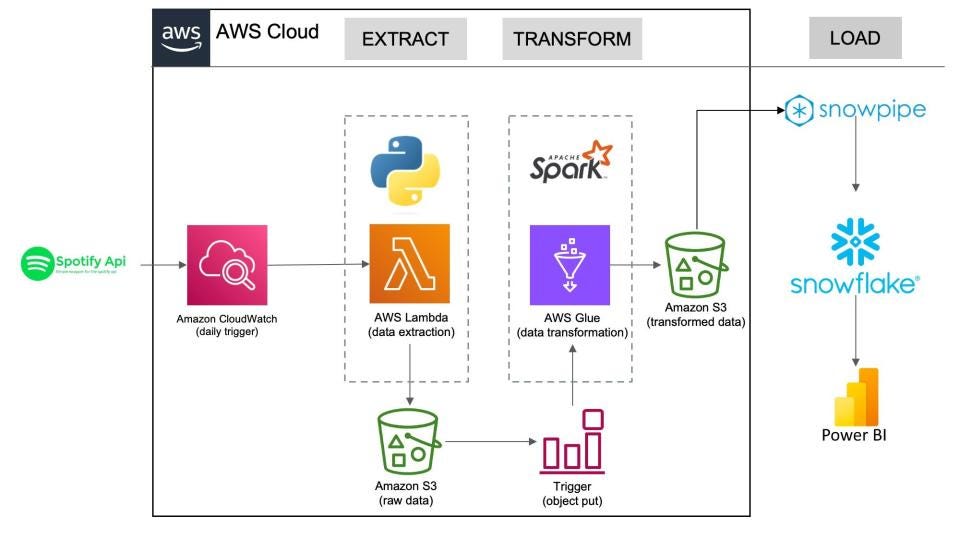
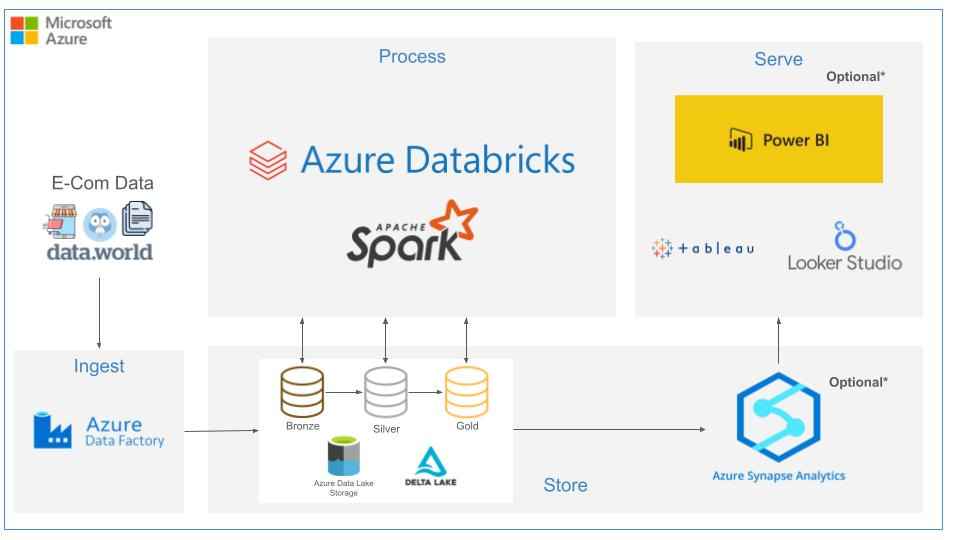
Then check out my course Apache Spark with Databricks for Data Engineers
Don’t forget to subscribe DataVidhya newsletter for high-quality content in the data field.